Finished Product Frontend Source Code Backend Source Code

MERN Full Stack Redux Axios React hooks Mongoose
MERN Stack Project Showcase

Charley Yoshi
Posted: April 30, 2023, 3:13 p.m.
Check out the website: catoapp.com
TL;DR
I made this cato (comments are turned off) full-stack website, allowing users to comment on youtube
videos that have their comment sections blocked.
This article covers the backend structures, including route setup, data handling and Mongoose
schema. On the frontend I used popular libraries such as Redux and Axios, and React’s `context` and
custom hooks for authentication. Finally it covers several problems I faced and solved.
Contents
- Overview
- Dividing Frontend and Backend Responsibilities
- Backend
- Frontend
- Features
- Problems Faced and Solved
- Packages & Libraries Used
- Lessons Learned
1. Overview
Welcome to the showcase of a dynamic MERN stack application crafted to tackle a common challenge:
enabling discussions on YouTube videos with disabled comments.
Named after the common frustration `comments are turned off`, cato harnesses the power of MongoDB,
Express.js, React, and Node.js to create a platform where users can share their thoughts and
opinions
seamlessly, especially on videos where comments are blocked.
In this article I will demonstrate my skills in full-stack development. All details will be
unveiled,
from a robust backend structure efficiently handling data to a user-friendly frontend ensuring a
smooth
experience. Let’s get started!
2. Dividing Frontend and Backend Responsibilities
The division between frontend and backend was essential for a smooth development.
The backend for my project, responsible for managing data flow and serving API endpoints, interacts
with
MongoDB through Mongoose schema, and of course handles requests from the frontend. Meanwhile, the
frontend, built with React and libraries like Redux for state management, focuses on providing an
intuitive UI and smooth user interactions.
The collaboration between these layers is achieved through RESTful API communication. Next I will
talk
about them one by one.
3. Backend
3.1 Folder Structure
I structured my backend folder as below:

Image: Folder structure
At its core are 4 specific paths (will be further discussed in 3.2) established in the
`server.js`, each of them
has their own router.
Routers are defined in a folder called `routes`, and are supposed to store request
handler functions,
such as get, post, or delete.
On the other hand, I have a folder called `controller`, which stores all the functions
that are used in
the request handler functions in the router files. Functions in this folder do the actual
heavy-lifting
job of handling and manipulating data, communicating with the database.
3.2 Setting up Routes (API Endpoints)
As I mentioned in the previous part, there were 4 paths to handle different functionalities in such
a video commenting application. They are actually `videos`, `comments`,
`votes`, and `user` paths. Below is an
image of how they look.

Image: The four main routes in the backend
The paths for `videos` and `user` are straight forward. It’s the
`comments` and `votes` that are
tricky. In a commenting system, a comment must point to one specific video, and a vote must point to
a specific comment (or reply). That’s why a videoID (:vid) will be passed into the path
for
comments, and a commentID (:cid) will be passed into the path for votes.
Below are the detailed endpoints for each path.
-
1.
/api/videos
Image: Detailed API Endpoints for `videoRoutes`
-
2.
/api/video/:vid/comments
Image: Detailed API Endpoints for `commentRoutes`
-
3.
/api/comment/:cid/votes
Image: Detailed API Endpoints for `voteRoutes`
-
4.
/api/user
Image: Detailed API Endpoints for `userRoutes`
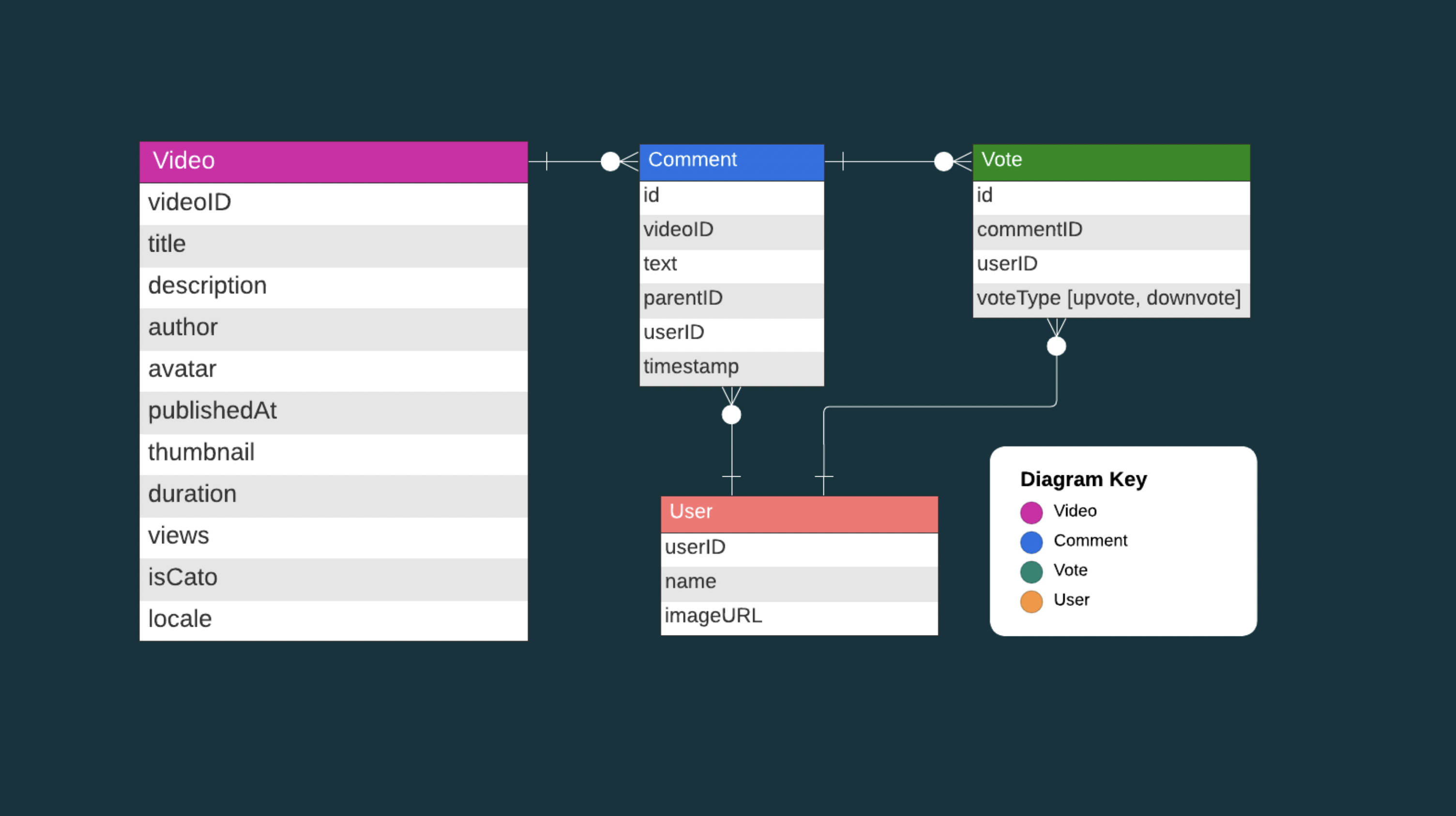
3.3 Mongoose Schema, Models and Structure
The project’s data architecture relies on four major Mongoose schemas, each designed to manage
specific aspects of the data flow:
-
1.
This schema captures essential video details, including`videoSchema`videoID,title,description,publishedAt(date of publishing),author,thumbnail,duration,views,isCatoflag (true is comments are turned off on Youtube),avatar, andlocale.
The above data is fetched from Youtube API v3. -
2.
Designed to handle comments, this schema holds data such as`commentSchema`vid(associated video ID),text(comment text),parentID(if it's a reply to another comment), anduserID(identifying the user who posted the comment). Additionally, ittimestampseach comment for tracking purposes. -
3.
Facilitating the voting system for comments, this schema stores`voteSchema`commentID(the comment being voted on),userID(identifying the user who cast the vote), andvoteType(either`upvote`or`downvote`). -
4.
Dedicated to managing user data, this schema includes`userSchema`userID(unique user identifier),firstName,lastName, andimageURL(user's profile picture).
Schema Design Considerations
When designing the schema for comments and votes, I was deciding between two approaches.
Approach 1 - Votes array within Comments
In this approach, votes are embedded within the comment schema, with two arrays`upvotes`
and
`downvotes`. It would look like this:
Comments {
commentID,
videoID,
userID,
Text,
upvotes:[user1, user2, …etc],
downvotes: [user1, user2, …etc]
}
Approach 2 - Separate Comment and Vote Schemas
Comments and votes are separated into different schemas.Each of the approaches has their own pros and cons. Approach 1 has a simpler data structure by storing comments as an array within the videos table, reducing the complexity of the database schema. Also, it might be easier to fetch comments and vote data together in a single query. However, it might hinder scalability and flexibility, especially when dealing with a large number of votes. The single table with an array might become less efficient for handling a large amount of items. Indexing and querying might become less performant. Also, it might lead to data redundancy since each comment row will contain all the votes. This can increase storage requirements and complicate data management.
On the other hand, Approach 2 has better data integrity, because each vote is linked to a specific comment through the
`commentID`, making it easier to maintain data consistency and
perform complex
queries. It is also better when it comes to scalability and flexibility which is very
important when
dealing with a large volume of data. The drawback is it might require more complex database schema
design and query logic, which might make development and maintenance more challenging.
Chosen Approach and Reasons
After some consideration, I decided to go for Approach 2, wherecomments and
votes are in separate
schemas, because it is better than Approach 1 in terms of scalability, flexibility
and data integrity.
It is also beneficial if the application is going to scale up in the long-term.
4. Frontend
4.1 Folder Structure and Libraries
For project organization and maintainability, the frontend react files are structured within the
src
directory like the following, ensuring a clear and scalable layout:
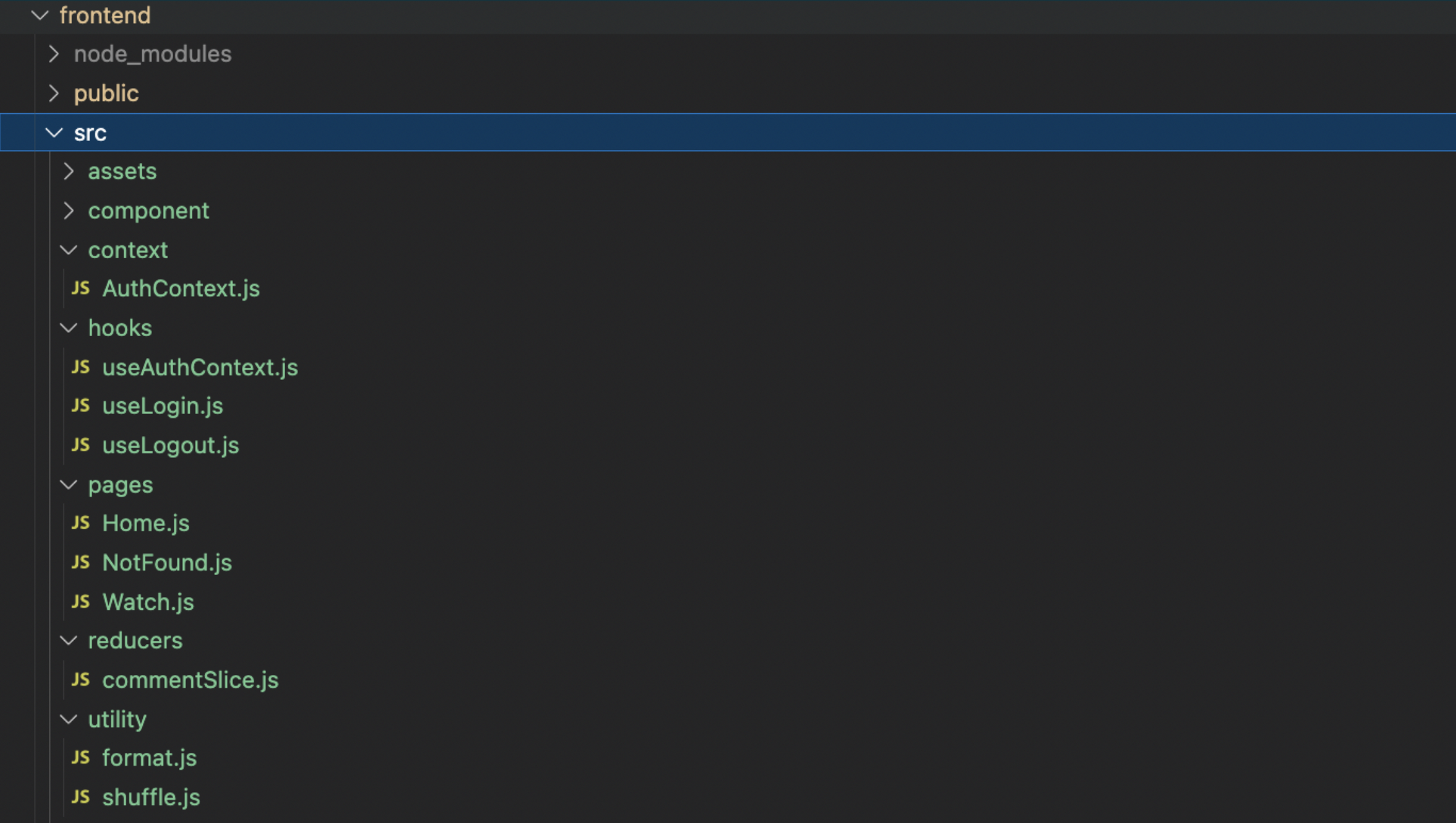
`assets`: for static images and non-code assets used across the application`components`: for reusable React functional components`context`: for custom context, e.g. AuthContext`hooks`: for custom hooks`pages`: for page-specific components, e.g. home page, 404 page, etc`reducers`: for Redux reducers`utility`: for utility functions and helper modules, e.g. formatting dates
- React:
The foundation of the frontend - Redux:
Centralized state management for data and actions within the application (explained in next section 4.2 Data Management) - Custom Context:
Handles specific needs for authentication (explained in next section 4.2 Data Management)
4.2 Data Management
-
1. Data Fetching with Axios
To fetch data from the backend, I used Axios, a robust HTTP client for making asynchronous requests. I chose to use Axios instead of the built-in fetch API because it is popular and widely used, supports more error handling capabilities, and has broader support for older browsers. Also, its built-in support for transforming data into json and the above reasons make it a preferred choice for backend communication.
-
2. State Management with Redux
As a centralized state management tool, Redux’s main purpose is to manage the state efficiently at the application-level. This tool comes in handy because when userspostnew comments to the video, it ensures real-time updates so that the user doesn’t have to reload the page to see the newly added comment. This seamless update mechanism enhances user experience by providing a more user-friendly interaction model.
-
3. Authentication with Custom Hooks, useContext & Google Identity
When it comes to authentication, I used a custom context that helps efficiently handle user authentication across the app. I created a context provider to wrap and encapsulate the whole application, which can then grant access to authentication data and methods /dispatchfunctions (e.g. login and logout) throughout the component tree.
To handle the actual user authentication, I used Google Identity so that users can use the`sign in with Google`button to login to my application, instead of going through the annoying process of registering a new user from scratch. When the user successfully login to their Google account, a jwt (JSON Web Token) is returned by the Google API.
By using this JSON web token along with implementing the custom context with useContext, the authentication information can be secured and accessed across different components. Users can also experience a fast, safe and familiar sign-in process.
4.3 UI/UX Implementation
I didn't do much of the design for the application. What I did was stick to the existing Youtube
website design as closely as possible. By replicating its layout, aesthetics, and functionalities,
users might find it easier to adapt and can find a seamless transition between YouTube and my
application. This may make them more comfortable using my app and thus enhance the user experience.
5. Features
5.1 App Logic
There are 3 key logics in this app that I want to talk about. First, there's the comment and voting
system in the app's frontend. Then, on the backend, there are two more: determining when to use
third party API calls, and finally how to handle user input on getting the corresponding
`videoID`.
Let's dive into each one to see how they work.
-
1. The Comment and Voting Logic (Frontend)
Commenting in this app is flexible - you can comment with your identity or anonymously. If you use the`sign in with Google`button, your comments will display your Google account's name; otherwise, they'll appear anonymously. I designed this setup to seek balance between user authorization and app usability, recognizing that many users hesitate to sign in to new apps.

GIF: Comment After Logging In

GIF: Comment Anonymously
On the other hand, voting isn't anonymous - you need to sign in to upvote or downvote a comment. This ensures that each user can only vote once on a comment, preventing multiple votes. It also allows me to track who voted for which comment using the`voteSchema`in the database (as stated in the previous section 3.3 Mongoose Schema, Models & Structure), linking theuserIDto thecommentIDandvote type. This way, I can show users if they've already voted on a comment by, for example, changing its colour on the page, providing a helpful visual cue for their previous interaction.
GIF: Vote After Logging In
GIF: Vote Anonymously
-
2. Determining When to Make Third-party API Calls (Backend)
Determining when to trigger the third-party API calls is crucial. Not only can excessive API calls be costly, but they can also impact the app's performance. Now, let's explore the methodology I used behind the two main third-party API I used for this app - Google Authentication and the YouTube API.
Google Authentication:
- Trigger: Whenever a user clicks the
`sign-in with Google`button. - Frequency: This call is made whenever needed due to its significance in ensuring the security and authentication of user access.
Youtube API:
- Trigger: There are two specific occasions prompt a call to the YouTube API.
- 1. VideoID Not Found: When the
videoIDisn't present in the app's database, a call is made to retrieve the video info and store it in my database. This prevents unnecessary calls by fetching data directly from the app's database when available. -
2. Updating Existing Video Info: When changes occur in the video details
stored locally (e.g., channel avatar update), a
patchrequest is sent to the YouTube API's endpoint to update the video information.
- 1. VideoID Not Found: When the
- Handling Changes Detection: Unfortunately, the existing YouTube API does not have a direct method to detect changes in video info. So far the most reasonable approach would be periodically re-fetching video info, e.g. on a weekly basis, to identify any alterations. This helps maintain an updated database and a seamless user experience.
- Trigger: Whenever a user clicks the
-
3. Getting Videos from User Input (Backend)
There are two methods I can get thevideoIDfrom users:
Direct Input Field: Providing users with an input field to paste the YouTube link, a common and straightforward method used on many websites for video conversion.
Custom URL Transformation: An alternative way by allowing users to replace`youtube`in the URL with`my-app-name`, enabling them to access the video via my app's domain.
Addressing Various YouTube Link Formats:
YouTube links can vary, including regular video URLs (like this:youtube.com/watch?v=0123456), shorts (like this:youtube.com/shorts/0123456), or videos within playlists (like this:youtube.com/watch?v=0123456&list=8765432). See more Active Youtube URL Formats. To ensure users can access the video they are looking for regardless of the link format, my backend logic employs several techniques such as regular expressions (regex) and parsing query parameters (e.g., useSearchParams hook) along with case handling methods to extract thevideoIDfrom the URL, so my app can recognize and process different YouTube link formats.
5.2 Localization
Locale-Based Recommendations:
I wanted the sidebar to provide recommended videos based on the user's locale. Initially, the plan was to scrape videos from various locales via the Youtube API to offer locale-specific recommendations. However, due to API limitations (that there’s no specific filter for comment-disabled videos), this method was expensive and inefficient.Adopting a Database-Based Approach:
Instead, I had this workaround: adding a`locale` field to the video model (as detailed in
section 3.3 Mongoose Schema Models and
Structure).
User locale information is obtained through JavaScript's `navigator.language` property.
Videos are then fetched from the database based on these locales.Leveraging User Contributions:
The videos in the database originate from users who searched for and commented on them. These existing user-generated entries serve as the basis for recommendations, so it is more likely that users find them relevant.This way I can transfer the recommendation workload to users, leveraging their preferences and saving backend resources from the task of sourcing videos.
5.3 Error Handling
Handling Intentional Errors:
In my project, some backend responses like 404 are intentional behaviours, not actual errors. The most common example is when handling requests for anonymous users.Graceful Error Handling Approach:
To manage these intentional errors more gracefully, I adjusted the backend to respond differently. Instead of a 404 'Not Found' status, the response now signifies the status of an anonymous user, using a`204 No Content` status code. This change ensures a more user-friendly approach by
explicitly stating
the absence of specific data for the anonymous user. 6. Problems Faced and Solved
I encountered key challenges, previously discussed in various sections. Here, I'll summarize these hurdles. I'll also highlight how I resolved these problems to ensure the app's success.
Challenges:
Central Data Store Management:Handling all application data in a centralized manner posed a challenge initially.
Third-Party API Call Frequency:
Managing and limiting the frequency of third-party API calls was a performance concern.
Database Schema Design:
Designing scalable and flexible database schemas presented challenges in determining the most efficient structure.
Solutions:
Redux for Centralized Data:Utilized Redux as a solution (as mentioned in 4.2 Data Management - State Management with Redux) to manage and maintain a central data store for certain application data.
Controlled API Call Frequency:
Developed some strategies (as mentioned in 5.1 App Logic - Features Determining When to Make Third party API Calls) to control and limit the frequency of third-party API calls, enhancing app performance.
Optimized Database Schema:
Addressed challenges by carefully designing database schemas (as mentioned in 3.3 Mongoose Schema, Models & Structure - Design Consideration) to create a scalable and flexible structure for improved efficiency.
7. Packages & Libraries Used
MERN Stack:
Employed the MERN (MongoDB, Express.js, React, Node.js) stack for comprehensive full-stack development.Mongoose:
For MongoDB object modelling, facilitating efficient schema creation and data handling.Redux:
For effective state management across the application, ensuring a centralized data store.Axios
For handling HTTP requests and managing data transfer between the frontend and backend.Emoji-Mart:
A library offering an emoji keyboard for enhanced user interaction and experience.
GIF: Emoji keyboard
Libraries for Improved User Experience:
Date-fns:
Transform date formats, converting timestamps to human-readable formats (e.g. from`2023-10-10` to `3 months ago`).
GIF: The change of format of views and date
React-String-Replace:
Convert plain text into timestamp format (e.g. from`00:00` to
clickable `<a>00:00<\a>`) for enhanced user experience.
GIF: Convert plain text into timestamp format
Linkify
Convert plain text into hyperlinks, enriching the displayed content with clickable links for improved usability.
GIF: Convert plain text into hyperlinks
React-Player
Implemented React-Player instead of iframes because it supports starting videos at specific seconds when clicking on timestamps (e.g.`01:20`), enhancing user control and experience.8. Lessons Learned
-
8.1 Technical Insights
Handling Global Context:
Learned to keep the user interface in sync with the database by managing the global context in the frontend.
Dispatch & Payload Understanding:
Figured out how to use hooks for easy login and authentication by understanding dispatch and payload concepts.
Enhanced Package Utilization:
Got better at utilising packages (such as using Date-fns to improve user experience).
-
8.2 Problem-Solving Skills
Adaptive Problem Solving:
Became more flexible in solving challenges like managing API calls, user authentication, and data presentation.
Project Scope Management:
Realized the importance of scalable database structures for future application growth and easier maintenance.
These lessons have not only enhanced my technical proficiency but also improved my problem-solving
skills and project management skills. I gained a better grasp of how development works and the
importance of always learning.
You've just finished reading: MERN Stack Project Showcase

Charley Yoshi
Posted: April 30, 2023, 3:13 p.m.

